这个 MySQL 索引选择性有点意思!
索引小伙伴们肯定经常用!但是有一种前缀索引不知道大家有没有用过或者听说过?今天松哥就来和大家聊一聊 MySQL 里边的这个前缀索引。
1.什么是前缀索引
所谓前缀索引说白了就是对文本的前几个字符(具体是几个字符在建立索引时指定)建立索引,这样建立起来的索引更小,所以查询更快。这有点类似于 Oracle 中对字段使用 Left 函数来建立函数索引,只不过 MySQL 的这个前缀索引在查询时是内部自动完成匹配的,并不需要使用 Left 函数。
那么为什么不对整个字段建立索引呢?一般来说使用前缀索引,可能都是因为整个字段的数据量太大,没有必要针对整个字段建立索引,前缀索引仅仅是选择一个字段的部分字符作为索引,这样一方面可以节约索引空间,另一方面则可以提高索引效率,当然很明显,这种方式也会降低索引的选择性。
这里又涉及到一个概念,什么是索引选择性?
2.什么是索引选择性
关于索引的选择性(Index Selectivity),它是指不重复的索引值(也称为基数 cardinality)和数据表的记录总数的比值,取值范围在 [0,1] 之间。索引的选择性越高则查询效率越高,因为选择性高的索引可以让 MySQL 在查找时过滤掉更多的行。
那有小伙伴要问了,是不是选择性越高的索引越好呢?当然不是!索引选择性最高为 1,如果索引选择性为 1,就是唯一索引了!这个时候虽然性能最好,但是也是最费空间的,这不符合我们创建前缀索引的初衷。
我们一开始之所以要创建前缀索引而不是唯一索引,就是希望能够在索引的性能和空间之间找到一个平衡,我们希望能够选择足够长的前缀以保证较高的选择性,但是又希望索引不要太过于占用存储空间。
那么我们该如何选择一个合适的索引选择性呢?索引前缀应该足够长,以便前缀索引的选择性接近于索引的整个列,即前缀的基数应该接近于完整列的基数。
首先我们可以通过如下 SQL 得到全列选择性:
1 | SELECT COUNT(DISTINCT column_name) / COUNT(*) FROM table_name; |
然后再通过如下 SQL 得到某一长度前缀的选择性:
1 | SELECT COUNT(DISTINCT LEFT(column_name, prefix_length)) / COUNT(*) FROM table_name; |
在上面这条 SQL 执行的时候,我们要注意选择合适的 prefix_length,直至计算结果约等于全列选择性的时候,就是最佳结果了。
3.创建前缀索引
举个例子,我们来创建一个前缀索引看看。
松哥这里使用的数据样例是 MySQL 自己提供的数据样例,SQL 脚本下载链接:https://downloads.mysql.com/docs/world_x-db.zip。
以这里的 countrylanguage 表为例,我们首先来看 Language 全列选择性:
1 | SELECT COUNT(DISTINCT Language) / COUNT(*) FROM countrylanguage; |

然后再来看前缀为 8 的选择性:
1 | SELECT COUNT(DISTINCT LEFT(Language, 8)) / COUNT(*) FROM countrylanguage; |
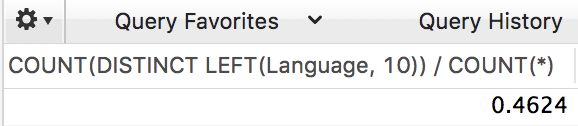
感觉似乎差不多,就是它了。
接下来我们为其创建前缀索引:
1 | alter table countrylanguage add index Language_index(Language(10)); |
查看刚刚创建的前缀索引:
1 | show index from countrylanguage; |

接下来我们分析查询语句中是否用到该索引:
1 | explain select * from countrylanguage where Language like 'Zu%'; |

可以看到,这个前缀索引已经用上了。
4.小结
好啦,今天就先聊这么多,剩下的我们以后再扯吧~
参考资料:
